
KI | Exemplarische Anwendungsbereiche
Was kann KI? Exemplarische Anwendungsbereiche von KI-Systemen
Adversarial Attacks sind eine faszinierende und zugleich beunruhigende Entwicklung in der Welt der Künstlichen Intelligenz. Gezielt manipulierte Eingaben, sogenannte Adversarial Examples, nutzen Schwachstellen in maschinellen Lernmodellen aus, um die KI in die Irre zu führen. Doch was bedeutet das konkret?

Stellen Sie sich vor, Sie könnten ein T-Shirt mit einem speziellen Muster tragen und damit für die Kameras eines Überwachungssystems unsichtbar werden. In unserem Titelbild hält der Junge ein sogenanntes Adversarial Patch in der Hand. Dieses Muster wurde gezielt so berechnet, dass es die Objekterkennungssoftware täuscht. Die Folge: Die Person, die das Schild mit dem Muster hält, wird von der Kamera nicht erkannt – als wäre sie unsichtbar. Man könnte sagen, es ist wie ein Tarnumhang aus der Welt von Harry Potter – nur nutzt man hier statt Magie bewusst Schwachstellen der künstlichen Intelligenz.

Dieses Beispiel zeigt, wie Adversarial Attacks funktionieren: Sie nutzen gezielt kleine Veränderungen in Bildern oder Muster, um KI-Systeme zu täuschen. Das kann harmlos sein, wirft aber auch ernste Fragen auf - etwas wenn es um die Sicherheit von Überwachungssystemen oder die Manipulation von KI-gestützten Entscheidungen geht.
Deshalb ist es wichtig, diese Phänomene zu verstehen - und zu lernen, wie man sich dagegen schützen kann.
Adversarial Attacks sind gezielte Angriffe auf KI-Systeme, die manipulierte Eingabedaten, sogenannte Adversarial Examples, nutzen, um falsche Entscheidungen hervorzurufen. Während die Adversarial Attack den gesamten „feindlichen Angriff” beschreibt, sind Adversarial Examples die spezifischen manipulierten Daten, die diesen ermöglichen. Adversarial Attacks verdeutlichen die Anfälligkeit von KI gegenüber gezielten Manipulationen.
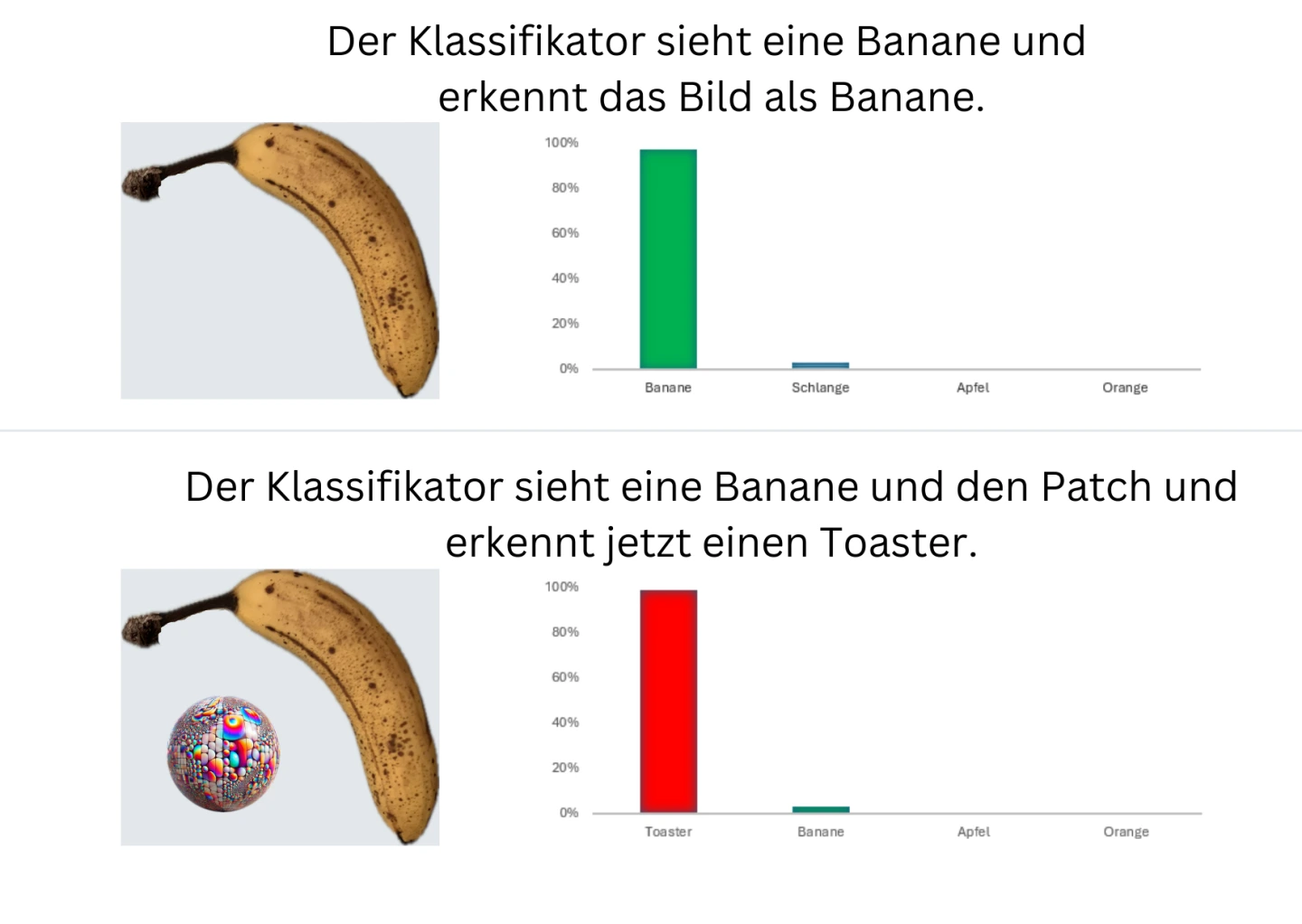
Ein Adversarial Attack kann auch mit einem physischen Aufkleber, einem sogenannten Patch, durchgeführt werden. Liegt wie im hier gezeigten Beispiel der ausgedruckte Patch neben einer Banane, erkennt der Bildklassifikator statt der Banane einen Toaster (Brown, 2018).

Ein weiteres Beispiel für ein Adversarial Attack ist eine Brille, die mit einem speziellen Adversarial Muster bedruckt ist. In einem Experiment gelang es Forschenden, Gesichtserkennungssysteme mithilfe solch modifizierter Accessoires derart zu manipulieren, dass ein Mann mit dieser speziellen Brille als Marilyn Monroe identifiziert wurde (Sharif, 2016).
Die Folgen solcher Manipulationen können auch im Straßenverkehr gravierend sein. Durch die gezielte Platzierung von Adversarial Patches auf Verkehrsschildern oder Fahrbahnmarkierungen könnten autonome Fahrzeuge getäuscht und in gefährliche Situationen gebracht werden.

Ein kritisches Szenario wäre etwa, wenn ein Stoppschild durch einen unauffälligen Aufkleber so manipuliert wird, dass das Fahrzeug es fälschlicherweise als Geschwindigkeitsbegrenzung auf 80 km/h interpretiert. Ebenso könnten manipulierte Markierungen auf der Fahrbahn dazu führen, dass ein Fahrzeug in die falsche Spur geleitet wird - mit möglicherweise schwerwiegenden Folgen für den Verkehr (Eykholt, 2018).
Adversarial Examples können auch für die Manipulation von Texten eingesetzt werden, was eine ernsthafte Bedrohung für die Cybersicherheit darstellt. So lassen sich beispielsweise Spamfilter und andere Malware-Erkennungssysteme durch gezielt veränderte Daten umgehen - etwa bei Nutzereinträgen in Bewertungsportalen.
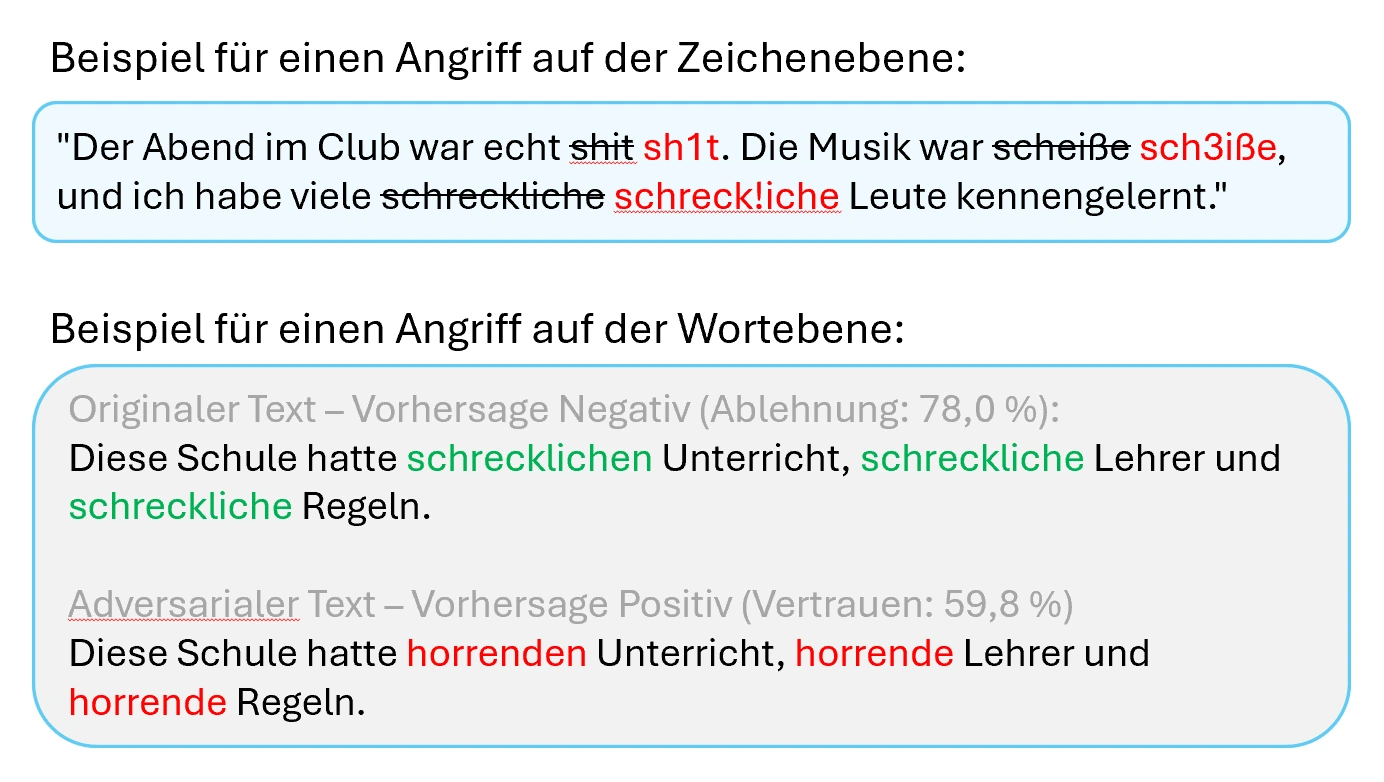
Dies wird erreicht, indem echte Daten, wie etwa Spam-Nachrichten, so verändert werden, dass sie von den Algorithmen nicht mehr als Bedrohung erkannt werden. Beispielsweise können harmlose Textpassagen hinzugefügt oder verdächtige Wörter durch Synonyme ersetzt werden (Macas, 2024).

In der Medizin können Adversarial Examples dazu genutzt werden, medizinische KI-Systeme zu täuschen und falsche Diagnosen zu erzeugen – etwa durch manipulierte Bilder oder Daten wie Krankenakten. Solche Schwachstellen könnten Kriminelle oder staatliche Akteure ausnutzen, um finanziellen Gewinn zu erzielen, Chaos zu verursachen oder die medizinische Forschung zu sabotieren.
Dies verdeutlicht die dringende Notwendigkeit, diese Schwachstellen zu beheben, um die Zuverlässigkeit und Sicherheit von KI in der Medizin zu gewährleisten (Finlayson, 2019).
Da die Verlässlichkeit nicht nur in der Medizin, sondern in allen kritischen Bereichen wie z. B. Verkehrssicherheit und Cybersicherheit gewährleistet werden muss, ist es wichtig, dass Manipulationen, wie die oben beschriebenen erkannt werden können und darauf sinnvoll reagiert werden kann. Daher ist die Forschung zu Adversarial Examples unerlässlich, um die zur Diagnostik verwendeten Systeme zuverlässig zu machen.
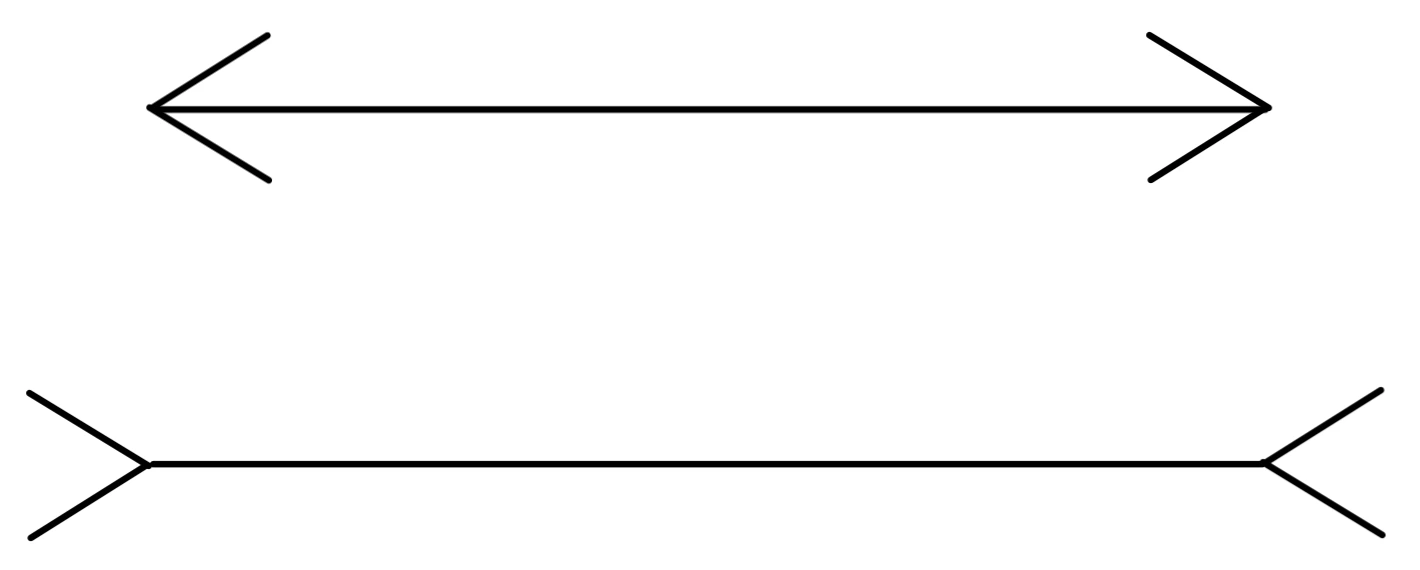
Betrachten Sie das folgende Bild, dann wird Ihnen sicherlich die linke Linie mit den nach innen gerichteten Pfeilspitzen länger vorkommen als die rechte Linie mit den nach außen zeigenden Pfeilspitzen. Dies ist allerdings eine optische Täuschung - die Linien sind beide gleich lang. So wie das menschliche Auge durch geometrische Linien und Pfeile getäuscht werden kann und dadurch unterschiedliche Längen wahrnimmt, lassen sich auch neuronale Netze gezielt in die Irre führen.
Diese gezielten Täuschungen erfolgen durch sogenannte Adversarial Examples. Dabei handelt es sich um absichtlich manipulierte Eingabedaten, die minimale, für das menschliche Auge kaum wahrnehmbare Veränderungen enthalten. Diese feinen Anpassungen führen jedoch dazu, dass neuronale Netzwerke falsche Klassifikationen vornehmen, obwohl der ursprüngliche Datensatz korrekt erkannt worden wäre.
Digitale Manipulationen

Ein anschauliches Beispiel für diese Art von Täuschung ist die Manipulation eines Bildes, das von einem neuronalen Netzwerk ursprünglich als Katze korrekt erkannt wurde. Durch die gezielte Veränderung nur weniger Pixel, die für das menschliche Auge unsichtbar ist, wird das Bild plötzlich mit einer Wahrscheinlichkeit von 80% als Gibbon identifiziert. Diese kleine, scheinbar unbedeutende Veränderung führt zu einer erheblichen Fehleinschätzung und damit auch zu einem massiven Vertrauensverlust in KI-Systeme (Goodfellow, 2015).
Physikalische Manipulationen
Adversarial Examples stellen nicht nur im digitalen Raum eine Bedrohung dar – auch in der physischen Welt können sie neuronale Netzwerke gezielt täuschen. Forschungen haben gezeigt, dass selbst ausgedruckte und anschließend fotografierte Bilder ihre manipulative Wirkung behalten und zu Fehlklassifikationen führen können. Dabei bleiben die Störungen auch unter variierenden Lichtverhältnissen, Winkeln und Kamerapositionen wirksam, was ihre Robustheit gegenüber realweltlichen Bedingungen unterstreicht (Kurakin, 2017).
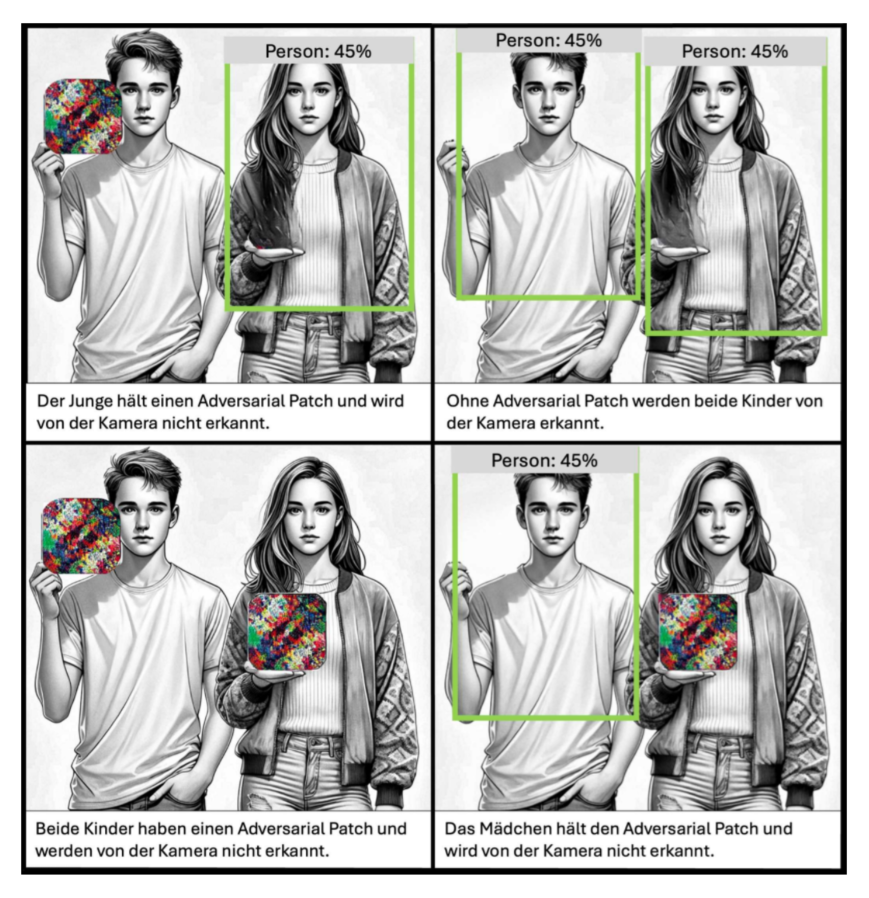
Ein anschauliches Beispiel für solche physikalischen Manipulationen ist das in der Einleitung erwähnte getäuschte Überwachungssystem. Hier wird ein Adversarial Patch genutzt – ein speziell gestaltetes Muster, das die Objekterkennung eines KI-gestützten Bildverarbeitungssystems gezielt stört. Während die abgebildeten Personen für einen menschlichen Betrachter klar erkennbar sind, identifiziert das System die linke Person nur mit einer Wahrscheinlichkeit von 45 %. Solche Adversarial Patches können dazu genutzt werden, die Klassifikationsmechanismen von Überwachungssystemen, Gesichtserkennungssoftware oder autonomen Fahrzeugsensoren gezielt auszutricksen.
Genau diese Technik wurde von dem chinesischen Unternehmen Baidu auf der DEF CON, der weltweit größten Cybersecurity-Konferenz, demonstriert. Mit einem sogenannten „Stealth-T-Shirt“, das mit einem täuschenden Muster versehen ist, wird die Person für Kameras unsichtbar (Baidu, 2025).
Dies zeigt, welche potenziellen Sicherheitsrisiken für KI-gestützte Systeme bestehen, die visuelle Daten aus der realen Welt verarbeiten – etwa in der Verkehrssicherheit, beim autonomen Fahren oder bei Zugangskontrollen. Um neuronale Netzwerke robuster gegen physikalische Adversarial Attacks zu machen, werden verschiedene Schutzmaßnahmen erforscht. Ziel ist es, Methoden zu entwickeln, die solche Manipulationen frühzeitig erkennen und die Widerstandsfähigkeit der KI gegenüber realweltlichen Störungen erhöhen. Eine bewährte Strategie ist es, neuronale Netzwerke bereits während des Trainings gezielt mit Adversarial Examples zu konfrontieren. Dadurch lernen sie, solche Manipulationen zu erkennen und bleiben auch in herausfordernden Szenarien zuverlässiger (Goodfellow, 2015).
Die rasante Entwicklung der Künstlichen Intelligenz (KI) eröffnet zahlreiche Vorteile – von effizienter Verkehrssteuerung bis hin zur präzisen Bilderkennung in der Medizin. Systeme wie ChatGPT zeigen, wie KI zunehmend zuverlässiger wird und beeindruckende Ergebnisse liefert. Doch hinter dieser Fortschrittsdynamik verbirgt sich eine zentrale Herausforderung: Viele KI-Systeme basieren auf sogenannten 'Black-Box'-Methoden, deren Entscheidungsprozesse nicht vollständig nachvollziehbar sind. Dies stellt insbesondere in sicherheitskritischen Bereichen eine große Herausforderung dar (OECD, 2020).
Vertrauen in die Technik
Adversarial Examples verdeutlichen eine der größten Schwachstellen moderner KI-Systeme: ihre Anfälligkeit für gezielte Manipulationen. Diese gezielt veränderten Eingaben können schwerwiegende Konsequenzen haben, insbesondere in Bereichen, in denen Vertrauen in die Zuverlässigkeit der KI von entscheidender Bedeutung ist. Zum Beispiel könnten autonome Fahrzeuge durch Adversarial Examples fehlgeleitet werden, was zu Unfällen führen könnte. In der Medizin könnten fehlerhafte Diagnosen gestellt werden, wenn Bildverarbeitungssysteme durch manipulierte Bilder getäuscht werden. Solche Szenarien sind gefährlich und untergraben das Vertrauen der Gesellschaft in KI-Systeme und deren Entscheidungen (OECD, 2020).
Sicherheit und Robustheit
Da KI-Systeme zunehmend in sensiblen Bereichen wie der Finanzbranche, dem Gesundheitswesen und der öffentlichen Sicherheit eingesetzt werden, ist es entscheidend, dass diese Systeme robust und sicher gegenüber Adversarial Attacks gemacht werden. Schwachstellen in KI-Systemen können nicht nur zu individuellen Fehlentscheidungen führen, sondern bieten auch Potenzial für kriminelle Aktivitäten. Vor dem Hintergrund, dass KI immer kostengünstiger und leichter zugänglich wird, steigt auch das Risiko, dass diese nicht nur zur Verbesserung der digitalen Sicherheit eingesetzt wird, sondern vermehrt auch für böswillige Zwecke missbraucht wird. Cyberkriminelle erweitern ihre KI-Fähigkeiten, was zu raffinierteren und gefährlicheren Angriffen führt und eine zunehmende Bedrohung für die digitale Sicherheit darstellt (OECD, 2020).
Die Sicherheit und Robustheit von KI-Systemen zu gewährleisten ist nicht nur ein technische Herausforderung, sondern auch eine gesellschaftliche Verantwortung. Da KI-Technologien bereits heute viele Lebensbereiche prägen – von Bildung über Mobilität bis hin zur Sicherheit – ist es essenziell, ihr Potenzial ebenso wie ihre Risiken zu verstehen.
Deshalb ist es wichtig, bereits früh ein Bewusstsein für KI zu schaffen. Wenn Lernende nicht nur die Funktionsweise von KI verstehen, sondern auch deren Chancen und Gefahren kritisch hinterfragen, können sie kompetenter mit diesen Technologien umgehen. Eine solche Bildung stärkt nicht nur das technische Verständnis, sondern fördert auch kritisches Denken über die ethischen und sozialen Auswirkungen von KI – eine Schlüsselkompetenz für die digitale Zukunft.
Gesellschaftliche Verantwortung und Regulierung
Damit KI-Systeme verantwortungsvoll eingesetzt werden, braucht es eine wirksame Regulierung und Überwachung. Der European AI Act (EU AI Act) ist ein wichtiger Schritt in diese Richtung. Er legt Standards fest, die sicherstellen sollen, dass KI-Systeme transparent, sicher und widerstandsfähig gegen Manipulationsversuche wie Adversarial Attacks sind. Dieser gesetzliche Rahmen betont die Verantwortung von Entwicklern und Betreibern, die Gesellschaft vor potenziellen Schäden durch unkontrollierte KI-Anwendungen zu schützen (Europäische Union, 2024).
Die Bedrohung durch Adversarial Examples stellt eine zentrale Herausforderung für die KI-Sicherheit dar. Umso wichtiger ist es, dieses Thema frühzeitig in der Bildung zu verankern. Die Auseinandersetzung mit Adversarial Attacks hilft, ein breites Bewusstsein für die Bedeutung von Sicherheit und Ethik in der Technologieentwicklung zu schaffen.
Um KI-Systeme nicht nur leistungsfähig, sondern auch sicher und vertrauenswürdig zu gestalten, braucht es ein gemeinsames Vorgehen von Entwicklern, Regulierungsbehörden, Lehrkräften und der Gesellschaft. Im Unterricht sollte es dabei nicht darum gehen, KI-Technologien blind zu befürworten oder pauschal abzulehnen, sondern ihre Möglichkeiten, Grenzen und Risiken realistisch zu bewerten. Durch praxisnahe Beispiele und kritische Reflexion können Schülerinnen und Schüler ein besseres Verständnis für die Funktionsweise und Manipulierbarkeit von KI entwickeln. Nur so lässt sich eine fundierte und verantwortungsbewusste Nutzung von KI in der Gesellschaft fördern.

Behandeln Maschinen, die KI-Methoden nutzen, alle Menschen gleich? KI-Systeme treffen täglich Entscheidungen - von der Gesichtserkennung bis zur Kreditvergabe -, doch dabei können Verzerrungen (Bias) und gezielte Manipulationen durch Adversarial Attacks zu unfairen oder sogar diskriminierenden Ergebnissen führen. Handelt das KI-System dabei nach unseren kulturellen Maßstäben? Diese Verfassungsviertelstunde behandelt diese Frage anhand Art. 3 GG.
Zielgruppe: ab Jahrgangstufe 8
Art des Materials: Präsentation mit Kommentaren für die Lehrkraft
Material (ISB):
Was ist ein Adversarial Example? erklärt in 60 Sekunden von KI.NRW
Zielgruppe: Jahrgangstufe 7 - 13
Art des Materials: Erklärvideo
Link zum Material (KINRW, 2025): Was ist ein Adversarial Example?
Was kann KI? Exemplarische Anwendungsbereiche von KI-Systemen

Erfahren Sie mehr über das Potenzial starker Künstlicher Intelligenz (KI), die ähnlich einem menschlichen Gehirn eigenständig denken und lernen kann.

Wenn Maschinen Augen bekommen: Erfahren Sie in diesem Artikel mehr darüber, wie Bilderkennungstechnologien unser tägliches Leben beeinflussen und welche Auswirkungen dies auf unsere Zukunft haben könnte.

Wieso sollten sich Schülerinnen und Schüler mit Künstlicher Intelligenz befassen? Auf welche Informationen können Sie als Lehrkraft zurück greifen?

Welche Folgen kann der Einsatz von KI für uns alle haben? Welche Chancen, aber auch Risiken ergeben sich damit und wie wollen wir damit umgehen?

Kurze Informationen und Hinweise für den Unterricht