
KI | exemplarische Anwendungsbereiche
exemplarische Anwendungsbereiche von KI-Systemen
Die künstliche Intelligenz (KI) ist nahezu täglich in den Medien präsent. Man könnte den Eindruck gewinnen, dass sie die Erfindung dieses Jahrhunderts ist. Jedoch ernten wir aktuell nur die Früchte der wissenschaftlichen Errungenschaften, deren Wurzeln bis in die 1950er Jahre zurückreichen. Lesen Sie hier, welche wichtigen Meilensteine aber auch Rückschläge die KI im Laufe der letzten Jahrzehnte erfahren hat.
Durch die Auseinandersetzung mit der Geschichte der KI können Sie die verschiedenen Technologien und Trends besser einordnen und zueinander in Beziehung setzen. Außerdem hilft der Blick auf die Meilensteine der KI, zukünftige Entwicklungen und Anwendungen von System, die KI-Methoden nutzen, besser einzuschätzen.



1950 warf der britische Mathematiker und Informatiker Alan Mathison Turing in seinem Artikel „Computing Machinery and Intelligence“ die Frage auf, ob eine Maschine denken kann. Anstatt die Begriffe „Maschine” und „Denken” zu definieren, schlägt er zur Beantwortung seiner Frage den folgenden Test vor: Eine Person, die im Folgenden als Anna bezeichnet wird, führt mittels eines Computerprogramms ein Gespräch mit zwei Gesprächspartnern, die sie beide nicht sehen kann. Anna weiß, dass es sich bei einem der Gesprächspartner um eine Maschine und bei dem anderen um einen Menschen handelt. Ihre Aufgabe ist es zu ermitteln, welcher Gesprächspartner der Mensch und welcher die Maschine ist. Wenn Anna im Gespräch nicht herausfinden kann, wer der Mensch und wer die Maschine ist, dann bedeutet dies laut Turing, dass Maschinen über ein ähnliches Denkvermögen wie Menschen verfügen. (Turing, 2021)

Obwohl der Test ein Meilenstein in der Geschichte der Künstlichen Intelligenz ist, ist er umstritten. Zum Beispiel setzt der Test das sprachliche Verhalten einer Maschine mit deren Fähigkeit zu Denken gleich: er unterscheidet nicht zwischen dem, was der Computer sagt und dem, was der Computer meint. Es macht jedoch nur dann Sinn, einer Person oder einer Maschine Gedanken zuzuschreiben, wenn sie auch wirklich meint, was sie sagt. „Es ist aber ohne Weiteres denkbar, dass unser Gegenüber grammatisch wohlgeformte Sätze von sich gibt, ohne damit etwas zu meinen“ (Gruber et al. 2015, S. 20).
Möglich wäre natürlich auch, dass eine Maschine „absichtlich“ scheitert. So lässt der deutsche Autor Marc-Uwe Kling in Qualityland einen seiner Protagonisten sagen: „Eine KI, die intelligent genug ist den Turing-Test zu bestehen, könnte auch intelligent genug sein ihn nicht zu bestehen.“
Trotzdem bleibt der Test bis heute ein wichtiges Konzept in der Künstlichen Intelligenz.

Der Begriff der Künstlichen Intelligenz wurde im Jahr 1956 von John McCarthy auf der von ihm organisierten Konferenz am Dartmouth College geprägt. Diese Konferenz hatte zum Ziel, herauszufinden, „wie man Maschinen dazu bringt, Sprache zu verwenden, Abstraktionen und Konzepte zu bilden, Probleme zu lösen, die derzeit dem Menschen vorbehalten sind und sich selbst zu verbessern.” (Minsky 1955; übersetzt in Russel/Norvig 2012, S. 40f) Obwohl keine neuen Durchbrüche erzielt wurden, hat diese Konferenz wesentlich zur Etablierung der künstlichen Intelligenz als eigenständiges Forschungsfeld beigetragen. Viele der teilnehmenden Forscher wie Marvin Minsky oder Claude Shannon beeinflussten im Anschluss das Feld nachhaltig.
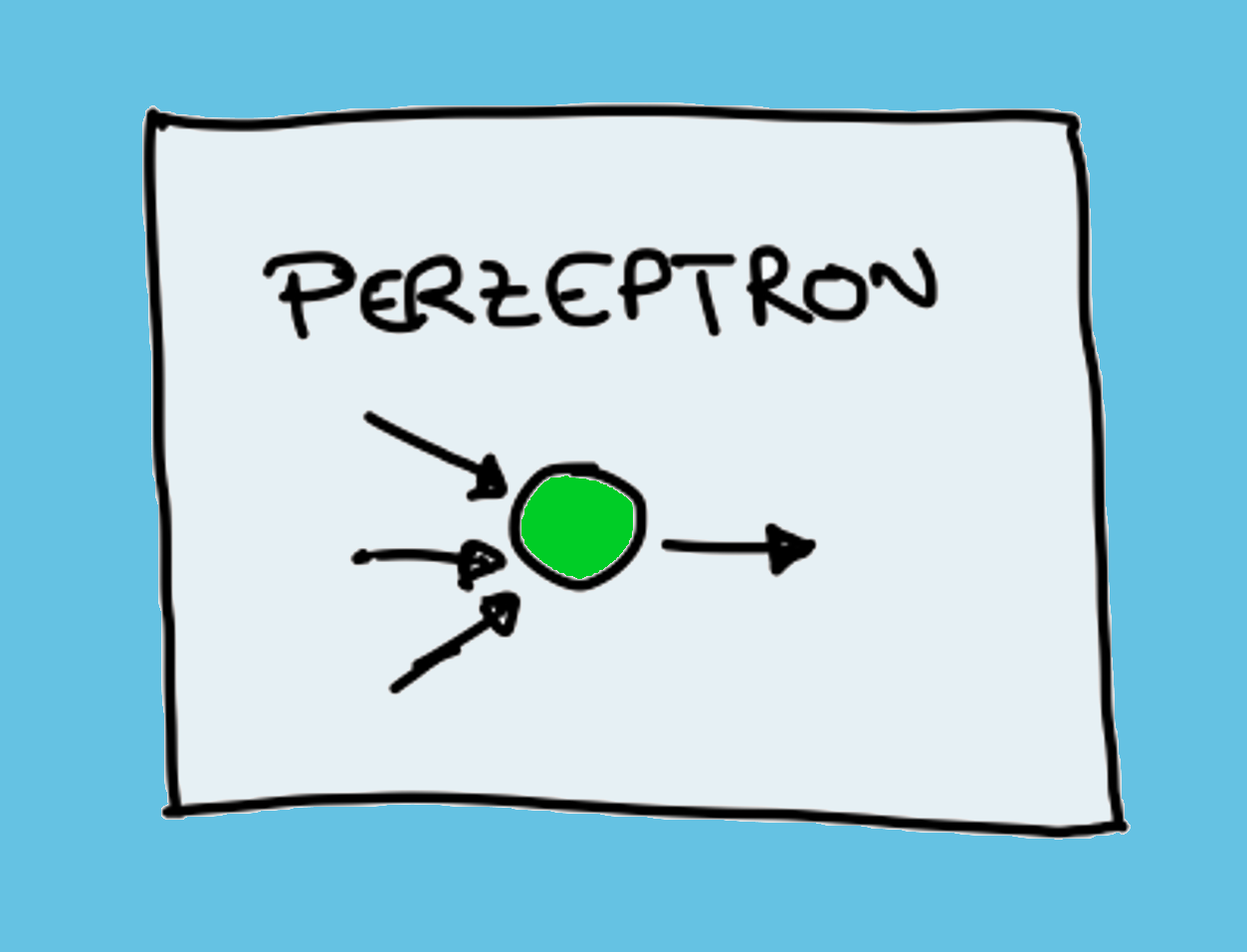
Schon in den 1950er Jahren entwicklelte der Psychologe Frank Rosenblatt ein lernfähiges künstliches Neuron – das sogenannte Perzeptron. Dieses einfache künstliche neuronale Netz schuf die Grundlagen für die Verfahren des maschinellen Lernens, auf denen die heutigen Erfolge moderner KI-Systeme beruhen. Kurze Informationen zu neuronalen Netzen finden Sie in dem folgenden Artikel.

Leider schnitt das Perzeptron damals gegenüber den Methoden der klassischen logischen Programmierung noch schlecht ab. So konnte es zum Beispiel die logische Funktion XOR nicht berechnen, mit der ein exklusives Entweder-Oder ausgedrückt werden kann (also zum Beispiel dass eine Person entweder Schokoladeneis ist oder Zitroneneis, aber nicht beide Sorten zusammen). Daher wurde die Forschung an neuronalen Netzen fast überhaupt nicht mehr unterstützt. Den Forschern war noch nicht bewusst, dass neuronale Netze mit mehreren Schichten diese und andere Probleme schnell behoben hätten. Die dazu geeigneten Lernverfahren wurden erst ca. 30 Jahre später entwickelt: Ab dem Jahr 1986 erlebte die Idee der künstlichen neuronalen Netze eine Wiederbelebung und wurde zu den fortschrittlichen Verfahren maschinellen Lernens weiterentwickelt, welche heute Anwendung finden. (Russell, Norvig 2012, S. 45, Lenzen 2020)
„Machine learning is concerned with the question of how to construct computer programs that automatically improve with experience.” [Tom M. Mitchell, Machine Learning, 1997, McGraw-HillScience]
“Das maschinelle Lernen ist der Teilbereich der KI, der sich damit befasst, Computer Probleme lösen zu lassen, ohne sie dafür explizit zu programmieren.“ (Schacht, Lanquillon, 2019, S. 90)
Die Umkehrung des EVA-Prinzips
Normalerweise löst ein Computer Probleme, indem er eine Eingabe in genau definierten Schritten zu einer Ausgabe umwandelt. Diese Schritte gibt ein Programmierer in einer eindeutigen Handlungsvorschrift zur Lösung des Problems– dem sogenannten Algorithmus – vor. Man bezeichnet dies auch als EVA-Prinzip (Eingabe, Verarbeitung, Ausgabe) der Informationsverarbeitung.
Beim maschinellen Lernen wird dieses grundlegende Prinzip der Informationsverarbeitung umgedreht: Statt den Algorithmus zur Problemlösung vorzugeben, werden beim maschinellen Lernen Algorithmen angewendet, die vorgeben, wie Erfahrungen zum Lernen genutzt werden können. „Man gibt den Algorithmen also nicht vor, wie sie ein Problem zu lösen haben, sondern stattdessen, wie sie aus den in Form von Daten vorliegenden Erfahrungen lernen können, das Problem [..] zu lösen“ (Kersting et al., 2019, S. 90).
Trainingsdaten als Grundlage
Um dies zu realisieren, muss also ein großer Erfahrungsschatz in Form von digital verfügbaren Daten vorliegen. Dies sind die sogenannten Trainingsdaten, die aus Eingabedaten bestehen, zu denen die gewünschte Ausgabe bekannt ist. Stellen Sie sich beispielsweise vor, dass Sie ein Programm erstellen möchten, das lernen soll zu entscheiden, ob sich auf einem Bild eine Katze befindet. Als „Erfahrungsschatz“ liegt eine große Menge an beschrifteten Tierbildern vor, wobei die Beschriftung angibt, welches Tier auf dem jeweiligen Bild abgebildet ist. Die gewünschte Ausgabe ist also bei diesen Trainingsdaten schon vorher bekannt.
Trainingsphase - das eigentliche „Lernen”
In der sogenannten Trainingsphase wird nun ein Modell anhand der Trainingsdaten schrittweise so angepasst, dass es „lernt”, eine Eingabe in die gewünschte Ausgabe zu überführen. Solch ein Modell ist zum Beispiel ein neuronales Netz oder ein Entscheidungsbaum. „Somit können Computer durch maschinelles Lernen ihre eigenen Programme schreiben und sind nicht auf die Programmierung durch den Menschen angewiesen.“ (Schacht, Lanquillon, S. 91).
Jedoch ist der Begriff des „Lernens“ in diesem Kontext mit Vorsicht zu genießen: „Auch wenn der Begriff maschinelles Lernen dies suggeriert, ein echtes Lernen, wie wir es als Menschen kennen, findet in der Lernphase nicht statt.“ (Schacht, Lanquillon, S. 91). Deswegen spricht man in anderen Fachbereichen auch eher von der „Anpassung eines Modells an Daten“ oder dem „Schätzen der Parameter eines Modells“. Das Modell kann nur mit einer bestimmten Wahrscheinlichkeit vorhersagen, welche Ausgabe richtig ist. „Letzendlich handelt es sich um ein Optimierungsproblem, bei dem basierend auf den gegebenen Trainingsdaten und unter Berücksichtigung einer konkreten Aufgabe (Ziel), das beste oder ein möglichst gutes Modell […] gesucht wird.“ (Schacht, Lanquillon, S. 91f)

Den ersten Chatbot entwickelte der deutsch-amerikanische Informatiker Joseph Weizenbaum (1923-2008) im Jahr 1966 zu Forschungszwecken. Mit ELIZA wollte er untersuchen, wie gut Kommunikation zwischen Mensch und Computer in natürlicher Sprache funktionieren kann. Der Chatbot wurde dabei so gestaltet, dass er eine bestimmte Art von Psychotherapeut simulieren sollte, der so antworten durfte, als wisse er nichts über die reale Welt. Z.B. konnte der Chatbot auf die menschliche Feststellung „Ich habe eine lange Bootsfahrt gemacht“ mit „Erzählen Sie mir über Boote“ antworten, wodurch die Unterhaltung glaubwürdig wirken sollte. Weizenbaum war vor allem überrascht, wie leicht sich Menschen täuschen ließen. Er berichtet: „Some subjects have been very hard to convince that ELIZA (with its present script) is not human“ (Weizenbaum, S. 42).

Als erster KI-Winter wird der Zeitraum in den späten 1960er und 1970er Jahren bezeichnet, in dem das Interesse an der künstlichen Intelligenz stark abnahm und viele Forschungsprojekte auf diesem Gebiet eingestellt wurden.
Die Gründe dafür waren vielfältig. Die Erfindungen und Durchbrüche in den Jahren zuvor führten zu unrealistischen Erwartungen. So gingen einige Forscher in den frühen 1970er Jahren noch davon aus, dass Maschinen innerhalb eines Jahrzehnts menschliche Intelligenz erreichen könnten. Allerdings waren die Computer in dieser Zeit noch nicht leistungsfähig genug, um komplexe Aufgaben wie Spracherkennung und Bildverarbeitung effizient lösen zu können. Die ausbleibenden Erfolge führten zu Enttäuschungen und abnehmendem Interesse, so dass viele Regierungen und Unternehmen die Finanzierung von Forschungsprojekten im Bereich der künstlichen Intelligenz reduzierten oder ganz einstellten. Dies bedeutet aber nicht, dass es in diesem Jahrzehnt keinerlei Entwicklungen auf dem Gebiet der KI gab, sie standen lediglich nicht im Fokus des öffentlichen Interesses (vgl. Lenzen 2020 und Russell, Norvig 2012, S. 44f)
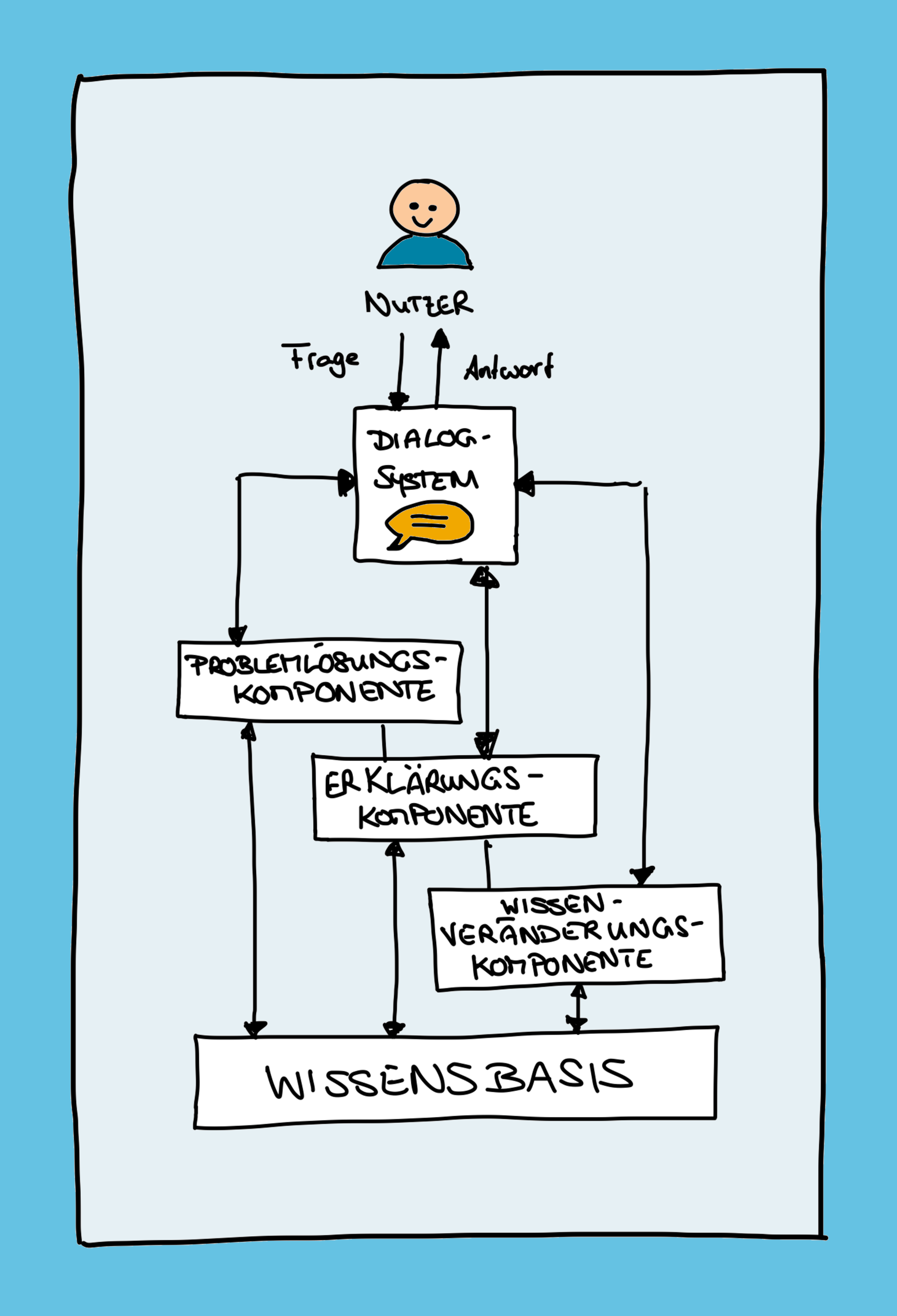
In den 1970er Jahren wurde der erste KI Winter durch die Entwicklung von Expertensystemen beendet. Expertensysteme sind Computerprogramme, mit denen das Spezialwissen menschlicher Experten über ein bestimmtes Sachgebiet sowie deren Schlussfolgerungsfähigkeiten nachgebildet werden. So werden Expertensysteme zum Beispiel in der Onkologie angewendet, um Ärzte und Pflegepersonal bei der Diagnose oder der Therapie von Krebspatienten zu unterstützen.
Die Nutzerin bzw. der Nutzer des Expertensystems gibt eine Frage über ein Dialogsystem ein, das diese zur Bearbeitung an die Problemlösungskomponente weiterleitet. Diese greift wiederrum auf die Wissensbasis zu, in der beispielsweise eine Sammlung von medizinischen Fakten sowie Wenn-Dann-Regeln gespeichert sind, die den aktuellen Kenntnisstand der betreffenden medizinischen Teildisziplin abbilden. Durch die Anwendung dieser Regeln und Fakten leitet die Problemlösungskompontente, welche auch als Inferenzmaschine bezeichnet wird, neues Wissen ab und löst das vom Nutzer gestellte Problem.
Die Erklärungskomponente des Expertensystems erläutert, wie die Schlussfolgerungen der Inferenzmaschine zustande gekommen sind. Dies ist äußerst wichtig, damit die Entscheidung, die durch das Expertensystem getroffen wurde, von der Nutzerin bzw. dem Nutzer nachvollzogen werden kann.
Wissen ist nicht statisch, sondern entwickelt sich ständig weiter. Daher muss es möglich sein, den aktuellen Stand des Wissens in das Expertensystems einzugeben. Genau dies ermöglicht die Wissensveränderungskomponente des Expertensystems. Sie bietet den Nutzerinnen und Nutzern des Expertensystems die Möglichkeit, der Wissensbasis neue Fakten und Regeln hinzuzufügen und sie somit auf den neusten Stand zu bringen.
(Styczynski et al. 2017, S. 11-14)
Ein einfaches Beispiel für eine Wenn-Dann-Regel, die in der Wissensbasis eines Kino-Expertensystems hinterlegt sein könnte, lautet „Wenn Sie ins Kino gehen möchten, dann müssen Sie eine Eintrittskarte kaufen.“ Fragt eine Nutzerin nun das Expertensystem, was sie tun muss, wenn sie ins Kino gehen möchte, dann leitet die Inferenzmaschine aus dieser Regel ab, dass sie eine Eintrittskarte kaufen muss.
Expertensysteme werden in Situationen eingesetzt, in denen die Entscheidungsregeln und Fakten klar und strukturiert erfasst werden können. Dies hat im Gegensatz zu lernenden Systemen den Vorteil, dass alle Entscheidungsregeln und alle mit ihnen getroffenen Entscheidungen jederzeit nachvollziehbar sind (Zweig 2019, S. 194 und Lenzen 2020).
Allerdings sind Probleme oft unstrukturiert und lassen sich nicht vollständig spezifizieren. Dies schränkt die Anwendungsgebiete von Expertensystemen stark ein. Auch der Aufbau und die Pflege der Wissenbasis stellen einen enormen Aufwand dar (Lenzen 2020). Diese und weitere Probleme führten nach dem anfänglichen Boom in den 1980er Jahren zu einer Ernüchterung gegenüber Expertensystemen (Karst, S. 1-2).
1981 kündigte Japan das sogenannte Computerprojekt der 5. Generation an (Russell, Norvig 2012, S. 48). Dieses hatte zum Ziel, innovative Computer zu entwickeln, die parallele Berechnungen und logische Programmierung nutzen, um so die technischen Beschränkungen herkömmlicher Computer zu überwinden. Sie sollten als Grundlage für die künftige Entwicklung künstlicher Intelligenz dienen (Kabaner S. 103; Rana S. 75). Wie schon vor dem ersten KI-Winter erwiesen sich diese Ziele als zu ehrgeizig und die Erwartungen als unrealistisch hoch. Das Scheitern dieses Projekts sowie die Ernüchterung gegenüber Expertensystemen führten zu einem zweiten KI-Winter.
Am 11. Mai 1997 gewann der IBM-Computer Deep Blue erstmals gegen den damals amtierenden Schachweltmeister Garry Kasparov (Pandolfini 1997, S. 7). Deep Blue basierte im Wesentlichen auf den Technologien der klassischen symbolischen KI: Er verfügte über einen großen Katalog von Eröffnungszügen und eine umfangreiche Bewertung von Stellungen. Basierend auf diesen konnte er Schachzüge effizient vorausberechnen. Deswegen stellte der Sieg methodisch keinen Meilenstein in der Geschichte der Künstlichen Intelligenz dar, rückte diese aber nach dem zweiten KI-Winter wieder ins Licht der Öffentlichkeit (Kossmann 2020, S.100f).
Die rasante Entwicklung im Bereich der KI lässt sich größtenteils mit den Fortschritten im Bereich des maschinellen Lernens, insbesondere des Deep Learnings (Tiefes Lernen), begründen. Deep Learning basiert auf sogenannten tiefen neuronalen Netzen, also solchen, die „üblicherweise Tausende, Millionen oder noch mehr“ künstliche Neuronen in mehreren verborgenen Schichten umfassen (Krohn, Beyleveld, Bassens, 2020).
Schon im obigen Beitrag zum Perzeptron wurde ersichtlich, dass die Idee der neuronalen Netze bereits in den 1950er Jahren entwickelt wurde. Dort mangelte es allerdings noch an Rechenleistung und zur Verfügung stehenden Daten, um die Technologie erfolgreich umsetzen zu können. Diese Einschränkungen gelten jedoch heutzutage nicht mehr, da die Rechenleistung enorm gestiegen ist und wir seit der Schaffung des World Wide Web einen exponentiellen Zuwachs von Daten erleben.
Ab dem Jahr 2012 gab es mehrere Durchbrüche auf den Gebieten der Sprach- und Bilderkennung durch den Einsatz tiefer neuronaler Netze. So errang das neuronale Netzwerk AlexNet im September 2012 einen überwältigenden Sieg bei der ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Dies ist ein Wettbewerb, der in den Jahren 2010 bis 2017 stattfand und dazu diente, den Fortschritt auf dem Gebiet der Bilderkennung und Klassifizierung zu fördern. Die spezielle, auf Bildverarbeitung und der Mustererkennung optimierte Architektur von AlexNet hat das Feld der Bilderkennung revolutioniert (Ranjan et al. 2020, S. 61). Seitdem haben solche Systeme Einzug in die Wirtschaft und unseren Alltag gefunden - etwa in Form von Sprachassistenten in Autos oder in automatisierten Sortieranlagen in der Landwirtschaft.
Go ist ein Brett- und Strategiespiel, das besonders in Asien sehr beliebt ist. Es gilt als weitaus komplizierter als Schach, da es viel mehr mögliche Stellungen hat. Viele Topspieler entscheiden daher intuitiv, welchen Zug sie als nächstes vornehmen, wodurch ihre Züge sehr schwer berechenbar sind. Trotzdem schaffte es das Programm AlphaGo, dieses Spiel zu erlernen und nach wenigen Trainingsmonaten den berühmten Go-Spieler Lee Sedol zu schlagen. Die Kernidee der Entwickler von AlphaGo bestand darin, anstatt nach dem Brute-Force-Verfahren alle möglichen Spielzüge auszuwerten, die Intuition des Menschen mit Methoden des maschinellen Lernens nachzuahmen. Mit dieser Strategie schlug AlphaGo den amtierenden Go-Weltmeister Lee Sedol im März 2016 (Sokolow, 2016).
Erklärbare künstliche Intelligenz (engl. Explainable AI - kurz XAI) hat zum Ziel, die Entscheidungsfindung und Funktionsweise einer künstlichen Intelligenz in einer für den Menschen verständlichen Weise zu erklären und zu visualisieren. Sie ist insbesondere bei kritischen Anwendungen in Bereichen der Medizin, dem Militär und der Rechtswissenschaft von Bedeutung, bei denen menschliche Entscheidungen auf der Grundlage von Empfehlungen getroffen werden, die von tiefen neuronalen Netzen erstellt wurden. Diese Systeme treffen ihre Entscheidungen in einem Black-Box-Vorgang, d.h. es ist nicht nachvollziehbar, wie das System zur Lösung seines Problems gelangt ist. Dabei gilt: Je mächtiger das tiefe neuronale Netz ist, desto weniger nachvollziehbar ist sein Entscheidungsprozess.
Ein wichtiger Meilenstein in der Entwicklung der XAI war das Jahr 2016, als die DARPA (Defense Advanced Research Projects Agency) ein Forschungsprogramm zur Entwicklung von erklärungsfähigen KI-Systemen ins Leben gerufen hat. Seitdem haben zahlreiche Forschungsprojekte und Initiativen das Thema XAI weiter vorangetrieben.

Seit den frühen 2020ern sind die rasanten Entwicklungen auf dem Feld der Künstlichen Intelligenz in den Medien präsent. Insbesondere generative KI-Systeme versetzen die Menschen in Erstaunen. Diese können nicht nur Routineaufgaben erledigen sondern auch sehr kreativ sein. Da diese Systeme zudem für eine breite Öffentlichkeit kostenfrei zugänglich gemacht wurden, lösten sie einen wahren KI-Boom aus.
Im November 2022 machte das US-amerikanische Unternehmen OpenAI den Chatbot ChatGPT öffentlich zugänglich. Schon innerhalb der ersten fünf Tage ab seiner Veröffentlichung registrierten sich eine Million Nutzer weltweit. GPT steht für „Generative Pre-trained Transformer“ und bezeichnet ein Sprachmodell, das darauf abzielt, sinnvolle, kohärente Antworten auf die schriftlichen Anfragen seiner Nutzer zu erzeugen. Die Antworten werden von einem tiefen neuronalen Netzwerk generiert, das darauf trainiert wurde, Muster und Beziehungen in Daten zu erkennen. Damit kann es Vorhersagen treffen oder eine breite Palette an Aufgaben in verschiedensten Bereichen erfüllen, von einfachen Fragen und Antworten bis hin zu komplexen kreativen Schreibaufgaben: Es kann ganze Aufsätze oder Reden schreiben, einfache mathematische Aufgaben lösen, Texte zusammenfassen oder Programme in unterschiedlichen Programmiersprachen schreiben. Dabei liegt der Fokus des Chatbots darauf, auf natürliche Weise mit seinem Nutzer zu interagieren. Dadurch entsteht beim Nutzer der Eindruck, dass er oder sie mit einem Menschen kommuniziert. Dies ist aber nur eine Illusion, da ChatGPT keine Zusammenhänge versteht sondern nur gemäß statistischen Zusammenhängen handelt und anders als ein Mensch nicht das versteht oder meint, was es von sich gibt.
Weitere textgenerierende Systeme anderer US-amerikanischer Technologie-Giganten wie der Bing Chat der Firma Microsoft (Februar 2023) oder Bard der Firma Google (März 2023) wurden kurz darauf veröffentlicht. Seitdem liefern sich diese und andere Unternehmen einen Konkurrenzkampf um Marktanteile und die fortschrittlichsten Sprachmodelle zur Verarbeitung und Erzeugung natürlicher Sprache.
Bildgenerierende Systeme (Midjourney, Stable Diffusion, Dall-E und Co)
Auch die Generierung von Bildern durch KI-Systeme wie Midjourney (Juli 2022), Stable Diffusion (August 2022) oder Dall-E (seit September 2022 allgemein verfügbar) hat eine enorme Aufmerksamkeit auf sich gezogen. Solche Systeme ermöglichen es, Bilder basierend auf den Texteingaben der Nutzer – sogenannten „Prompts“ - zu erzeugen. Die Möglichkeit, Kreativität „auf Knopfdruck“ abzurufen und damit qualitativ hochwertige Bilder zu erzeugen, übt eine hohe Faszination aus, führt aber auch direkt zu Fragen des Urheberrechts, der Zukunft kreativer Berufe und der Möglichkeit zur Verbreitung von Deep Fakes, also kaum zu erkennender fehlerhafter Bildinformationen.
Neben den oben beschriebenen text- und bildgenerierenden Systemen gibt es eine ganze Reihe weiterer KI-Anwendungen wie zum Beispiel zur Generierung von Musik, Stimmen oder Videos.

Erwartungen an moderne KI-Systeme
Die hohen Erwartungen an moderne KI-Systeme spiegeln sich in den eindrucksvollen Vergleichen wider, mit denen versucht wird, ihre potentiellen Auswirkungen in Worte zu fassen. So bezeichnete Andrew Ng KI als „neue Elektrizität“ (Lynch, 2017). Auch der häufig verwendete Begriff der KI-Revolution verdeutlicht die grundlegenden, radikalen und nachhaltigen Veränderungen, die die Entwicklungen auf dem Gebiet der KI in den letzten Jahren mit sich gebracht haben. Dabei werden Parallelen zu früheren Industriellen Revolutionen gezogen: Während in der Vergangenheit Maschinen die körperliche Leistungsfähigkeit des Menschen verbesserten, wird erwartet, dass sie in der Ära der KI die geistigen Fähigkeiten von Menschen ergänzen und erweitern. (Bughin & Hazan, 2017)

Risiken moderner KI-Systeme
Doch nicht nur die Erwartungen an die KI-Revolution sind hoch. Wie jede Revolution hat sie weitreichende Auswirkungen auf die Gesellschaft als Ganzes und verläuft nicht reibungslos. Viele der oben beschriebenen generativen KI-Systeme werden von Menschen als faszinierend und beängstigend zugleich wahrgenommen (dpa, 2024). Beeindruckend sind beispielsweise Systeme zur simultanen Videoübersetzung, die in einer Sprache eingegebene Texte innerhalb kürzester Zeit in eine andere Sprache übersetzen und lippensynchron wiedergeben (Gramlich und Beck, 2023).
Allerdings ist das Missbrauchspotential solcher Systeme hoch, zum Beispiel in Form von Anrufen mit durch KI generierten oder manipulierten Stimmen. Der niedrigschwellige Zugang, die erhöhte Verfügbarkeit und die relativ einfache Bedienbarkeit solcher KI-Tools ermöglicht es auch Laien, sogenannte Deepfakes zu erzeugen. Als Deepfakes bezeichnet man realistisch wirkende, aber gefälschte Medieninhalte wie zum Beispiel Gesichter oder Stimmen in Videos, Audiodateien oder Fotos. Da diese KI-erstellten Medieninhalte täuschen echt sind, können sie von Menschen nur schwer als Manipulationen erkannt werden (Robertz, 2023). Somit müssen wir uns von der herkömmlichen Vorstellung verabschieden, dass ein Video oder Bild als unumstößlicher Beweis gilt. Ende März 2023 verbreitete sich beispielsweise das täuschend echt aussehende, KI-generierte Bild vom Papst im hippen Daunenmantel rasend schnell in den sozialen Netzwerken. Viele Menschen hielten das Foto für echt. Was bei diesem Bild zunächst witzig erscheint, kann zum Beispiel in politischen Kontexten wie Wahlkämpfen schwerwiegende Folgen haben, da die Möglichkeit besteht, gefälschte Bilder oder Videos zu generieren und zu Desinformationen verbreiten. (Klaus, 2023)

Als digitale Gegenmaßnahme gibt es hier zum Beispiel KI-Bilddetektoren, mit denen überprüft werden kann, ob ein vorliegendes Bild von einer KI generiert wurde.
Allerdings kann man sich auf solche Detektoren nicht hundert prozentig verlassen. Die Fähigkeiten, Fakten zu überprüfen, unechte Bilder und Videos von echten zu unterscheiden und eine gesunde kritische Distanz zu Medieninhalten zu haben, werden somit wichtiger denn je. (Gerl, 2023)
Regulierung von KI
Diese wenigen Beispiele lassen erahnen, wie bisherige grundlegende gesellschaftliche Konzepte angepasst und neue Fähigkeiten erlernt werden müssen. Dem daraus resultierenden Wunsch nach einer Regulierung der Möglichkeiten von KI, etwa durch eine Kennzeichnungspflicht für KI-generierte Inhalte, ist die EU mit dem am 13.3.2024 verabschiedeten KI-Gesetz nachgekommen. Es ist der weltweit erste umfassende Rechtsrahmen für KI mit dem Ziel, eine „vertrauenswürdige KI in Europa und darüber hinaus zu fördern, indem sichergestellt wird, dass KI-Systeme die Grundrechte, die Sicherheit und die ethischen Grundsätze achten.” (Europäische Kommission, 14.3.2024)
Das KI-Gesetz verfolgt einen risikobasierten Ansatz, bei dem das rechtliche Eingreifen auf das Risiko-Niveau des jeweiligen KI-Systems zugeschnitten ist. Dazu unterscheidet das Gesetz zwischen den in der folgenden Grafik dargestellten vier Risiko-Stufen.
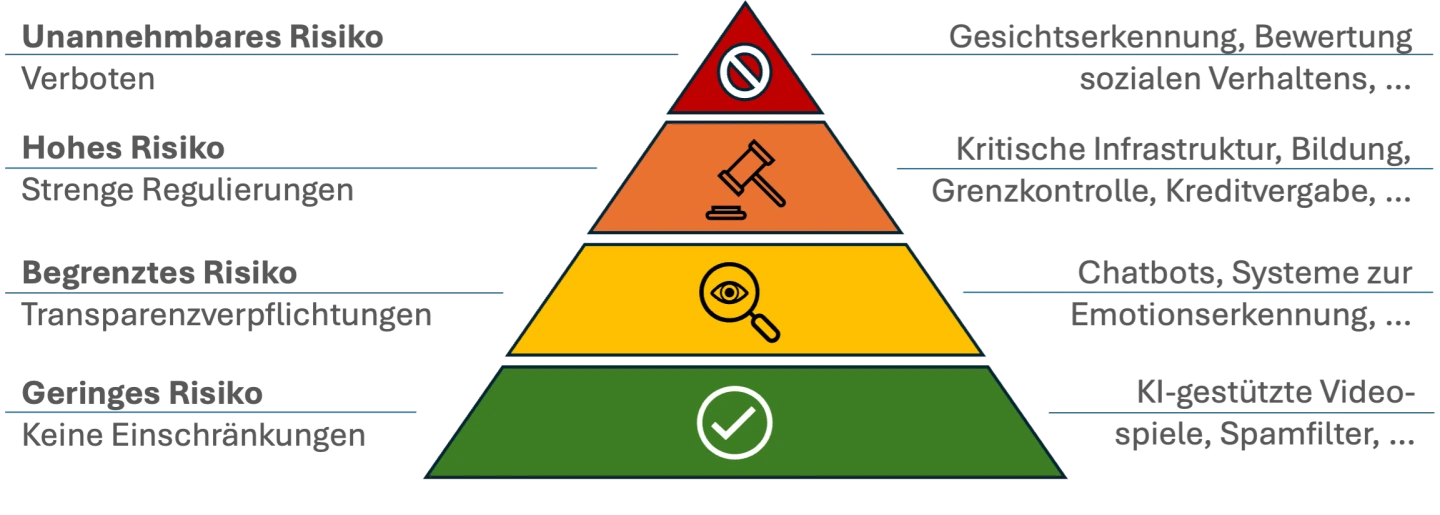
Die EU strebt eine umfassende Regulierung aller KI-Systeme an, steht jedoch vor der Herausforderung, dass es keine einheitliche Definition von KI gibt. Daher verwendet sie eine breite Definition von KI, die auch zukünftige Entwicklungen im KI-Bereich im Blick hat. Denn wie schon der Name „KI-Frühling” für die frühen 2020er Jahre suggeriert, stecken KI-Systeme derzeit noch in den Kinderschuhen. Obwohl es seit den 1950er Jahren schon verschiedene Phasen des KI-Hypes gab, scheint es diesmal, als ob die KI dauerhaft bleiben wird.
exemplarische Anwendungsbereiche von KI-Systemen

Welche Folgen kann der Einsatz von KI für uns alle haben? Welche Chancen, aber auch Risiken ergeben sich damit und wie wollen wir damit umgehen?
Kurze Informationen und Hinweise für den Unterricht
Woher haben Chatbots ihr Können und was bedeutet das für uns?

Textbasierte KI-Technologien didaktisch zielführend im Unterricht einsetzen - Ideen und Beispiele

Angesichts der Verbreitung von KI stellt sich die kritische Frage nach der Datenzuverlässigkeit und wie Verzerrungen entstehen: Welche Auswirkungen hat dies auf Diskriminierung?